
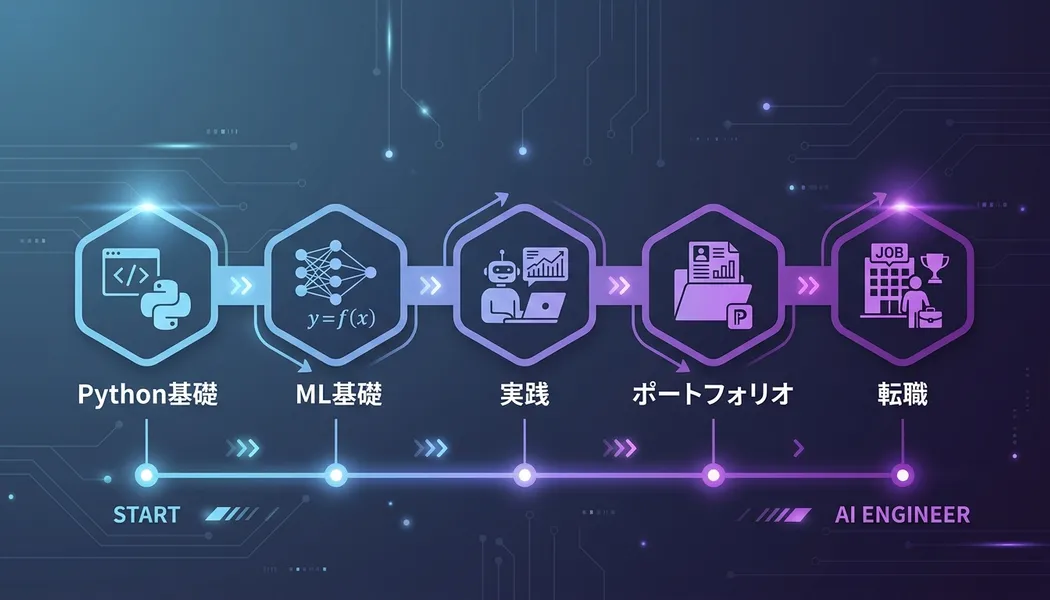
AIエンジニアへの道のりを正確に理解する
「AIエンジニアになりたい」という人が増えている一方で、何からどの順番で学べばいいかわからず、学習が途中で止まるケースが多い。
よくある失敗パターンは2つだ。
1つ目は「Pythonを学んでいきなり深層学習の本を読み始める」という基礎スキップ型。機械学習の動作原理を理解するための数学・データ操作スキルがないまま進むと、コードを写経することはできても、エラーが出たときに何が起きているかわからなくなる。
2つ目は「ChatGPT APIを使ってアプリを作る」だけで完結する表面活用型。生成AIを使ったプロダクト開発は重要なスキルだが、機械学習の基礎がなければ「なぜそうなるか」の説明ができず、面接での質問に答えられない。
このロードマップでは、完全未経験からAIエンジニアとして転職可能なレベルに達するまでの4つのフェーズを解説する。各フェーズで何を習得し、何をアウトプットするかを明確にすることで、学習の迷子になることを防ぐ。
フェーズ1: Python基礎(1〜2ヶ月)
AIエンジニアへの旅の出発点はPythonだ。機械学習のコードはほぼすべてPythonで書かれており、ライブラリも豊富に存在する。

Phase 1で習得すること
基本文法の習得
まず以下の文法要素を「書ける」レベルにする。コードを読めるだけでは不十分だ。自分の手でエラーが出たとき、何が原因かを特定できるレベルを目指す。
- 変数・データ型(int, float, str, list, dict, tuple, set)
- 条件分岐(if/elif/else)
- ループ(for, while, 内包表記)
- 関数の定義と呼び出し
- クラスとオブジェクト指向の基礎
- 例外処理(try/except)
- ファイル操作(読み書き、CSV)
- 外部ライブラリのインストールと使用(pip)
- 仮想環境の管理(venv)
フェーズ1完了の目安
次の課題を辞書なしで解けるようになれば次に進んでよい:
- CSVファイルを読み込んで特定の条件で行をフィルタリングする
- リストの中から重複を除いた要素数を返す関数を書く
- APIからデータを取得してJSONとして保存する
Phase 1のおすすめ教材
| 教材 | 費用 | 特徴 |
|---|---|---|
| Progate Python | 月額990円 | 視覚的でわかりやすい。初心者に最適 |
| paizaラーニング Python入門 | 月額1,078円 | 問題演習が豊富 |
| Python公式チュートリアル | 無料 | 英語だが網羅的で正確 |
| 「Pythonチュートリアル」オライリー | 約4,000円 | 辞書代わりに手元に置くと便利 |
週あたりの学習時間の目安: 15時間
フェーズ2: データ分析・機械学習基礎(3〜4ヶ月)
Pythonの基礎ができたら、機械学習の核心であるデータ操作と機械学習の基礎理論を習得するフェーズだ。
Phase 2で習得すること
データ分析ライブラリ
# 機械学習で必須の4大ライブラリ
import pandas as pd # データ操作・前処理
import numpy as np # 数値計算
import matplotlib.pyplot as plt # データ可視化
import seaborn as sns # 統計的可視化
pandasの習得に最も時間を使うべきだ。実務のデータはほぼ必ずpandasで前処理される。
習得すべきpandasの操作:
- データの読み込み・書き出し(CSV、Excel、JSON)
- インデックス・列操作(rename, drop, set_index)
- データのフィルタリング(loc, iloc, query)
- 欠損値の処理(fillna, dropna)
- グループ集計(groupby, agg)
- 結合(merge, join, concat)
- 時系列データの扱い
機械学習の基礎理論
| アルゴリズム | 用途 | 難易度 |
|---|---|---|
| 線形回帰 | 数値予測 | ★★☆☆☆ |
| ロジスティック回帰 | 二値分類 | ★★☆☆☆ |
| 決定木 | 分類・回帰 | ★★★☆☆ |
| ランダムフォレスト | アンサンブル学習 | ★★★☆☆ |
| 勾配ブースティング(XGBoost) | 高精度予測 | ★★★★☆ |
| k-meansクラスタリング | 教師なし学習 | ★★☆☆☆ |
scikit-learnを使ってこれらのアルゴリズムを実装し、モデルの評価(精度、適合率、再現率、AUC)まで理解する。
Phase 2のアウトプット
Kaggle タイタニックコンペを完走する
Kaggleのタイタニックはデータ分析・機械学習の登竜門だ。以下の流れで1本完走することがPhase 2の卒業条件だ。
- データの読み込みとEDA(探索的データ分析)
- 欠損値の処理と特徴量エンジニアリング
- モデルの学習と評価(複数アルゴリズムの比較)
- ハイパーパラメータのチューニング
- Kaggleへのsubmit
フェーズ3: 深層学習・LLM実装(3〜4ヶ月)
機械学習の基礎ができたら、現在のAI業界で最も注目されている深層学習とLLM(大規模言語モデル)の実装を学ぶ。
Phase 3で習得すること
深層学習フレームワーク
PyTorchが現在の業界標準だ。研究分野でも本番運用でもPyTorchの採用が多く、求人票でもPyTorchの記述が圧倒的に多い。
# PyTorchの基本的な学習ループ
import torch
import torch.nn as nn
import torch.optim as optim
# モデルの定義
class SimpleClassifier(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.network(x)
# 学習ループの骨格
model = SimpleClassifier(784, 256, 10)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
LLMアプリ開発
2025〜2026年のAIエンジニア求人で最も求められているスキルだ。OpenAI・Claude(Anthropic)・Gemini(Google)のAPIを使ったアプリ開発を習得する。
# LangChainを使ったRAGの基本構成
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ベクトルストアの構築
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(docs, embeddings)
# 検索・回答チェーンの構築
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 4})
)
Phase 3で習得すべき技術一覧:
| 技術 | 優先度 | 理由 |
|---|---|---|
| PyTorch基礎 | 高 | 深層学習の標準フレームワーク |
| OpenAI/Claude API | 高 | LLMアプリ開発の基礎 |
| LangChain | 高 | RAG構築で広く使われる |
| ベクトルDB(Chroma/pgvector) | 中 | RAGに必要 |
| Hugging Face Transformers | 中 | 事前学習モデルの活用 |
| FastAPI | 中 | MLのAPI化で頻出 |
| Docker | 中 | 本番デプロイに必要 |
Phase 3のアウトプット
以下のいずれかをGitHubで公開することがPhase 3の卒業条件だ。
推奨プロジェクト1: 社内ドキュメント検索システム(RAG)
- PDFや社内Wikiを読み込み、自然言語で検索できるシステム
- LangChain + Chroma + FastAPI で構築
- StreamlitやNext.jsでフロントエンドも作ると差別化になる
推奨プロジェクト2: 画像分類WebAPI
- ResNetなどの転移学習を使った画像分類モデル
- FastAPIでAPI化し、コンテナ化してデプロイ
- 独自データセットで学習することでオリジナリティが出る
推奨プロジェクト3: LLMを使った業務改善ツール
- 議事録要約、コードレビュー支援、ドキュメント生成など実務で使えるもの
- 実際に使い続けることで「本当に役立つか」を体感できる
未経験からAI・機械学習エンジニアになるための完全ロードマップ
Python学習から機械学習、転職活動まで12〜18ヶ月の詳細ロードマップ。各フェーズの教材選びに役立つ
フェーズ4: 転職活動(1〜2ヶ月)
技術スキルが整ったら転職活動に移る。このフェーズでは技術スキルを「採用に通る形」に変換することが目標だ。

ポートフォリオの最終整備
Phase 3で作ったプロジェクトを転職活動に使える状態に整える。
必須チェックリスト:
- READMEに「何を作ったか・なぜ作ったか・技術選定の理由・成果・課題」が書かれている
- コードに適切なコメントが付いている
- デプロイしてURLで触れる状態になっている(Hugging Face Spaces、Renderなど無料で可能)
- GitHubのコミット履歴が整理されている(大量の「fix」コミットは整理する)
職務経歴書の書き方
未経験転職で最も重要なのは「ポテンシャルの見せ方」だ。以下の構成で書く。
1. 技術スキルサマリー 習得したスキルを一覧で記載する。「〇〇ができる」という形で具体的に。
2. プロジェクト実績 ポートフォリオの各プロジェクトについて、技術スタック・期間・工夫した点・成果を記載する。
3. 学習の継続性
- 週何時間学習しているか
- 読んだ技術書・受講した講座
- Kaggle参加歴・ランキング
転職エージェントの活用
未経験AIエンジニアの転職では、エージェントの選択が重要だ。
エージェント選びのポイント:
- AI・機械学習の求人を扱っているか
- アドバイザーがエンジニア経験者か
- ポートフォリオのフィードバックをしてもらえるか
- 非公開求人にアクセスできるか
面接で聞かれること
AIエンジニアの面接では技術的な質問と実績の両方が問われる。
頻出の技術質問:
- 過学習とは何か、どう防ぐか
- TransformerのAttentionメカニズムを説明してください
- RAGとFine-tuningの違いと使い分けを教えてください
- ベクトルデータベースを使う場面はどんなときですか
- LLMのトークンとコストの関係を説明してください
ポートフォリオに関する質問:
- このプロジェクトでどの技術を選んだか、なぜか
- 一番困ったことと、どう解決したか
- このシステムをスケールするとしたらどう変えるか
- セキュリティ上のリスクはどこにあるか
スクールvs独学:どちらを選ぶか
独学とスクールにはそれぞれ明確なトレードオフがある。
| 観点 | 独学 | スクール |
|---|---|---|
| コスト | 数万円以内 | 10〜60万円 |
| 期間 | 1.5〜2年 | 0.8〜1.2年 |
| 挫折リスク | 高い | 低い |
| 転職サポート | なし | あり |
| 自由度 | 高い | カリキュラム依存 |
| 向いている人 | 自己管理できる、技術的な問題を解決できる | 体系的に学びたい、転職サポートを受けたい |
プログラミング経験がまったくない場合、独学の挫折率は高く、スクールで体系的に学ぶ方が遠回りにならないケースが多い。
プログラミング独学で転職する現実
独学1000時間の実態と、スクールとの比較。自分に向いているルートを判断するための正直な情報
まとめ
未経験からAIエンジニアへの道は長いが、ロードマップが明確であれば迷子になることなく進める。
4フェーズのまとめ:
- Phase 1(1〜2ヶ月): Python基礎。変数・関数・クラス・ファイル操作
- Phase 2(3〜4ヶ月): データ分析・機械学習基礎。pandas、scikit-learn、Kaggle
- Phase 3(3〜4ヶ月): 深層学習・LLM実装。PyTorch、LangChain、ポートフォリオ作成
- Phase 4(1〜2ヶ月): 転職活動。ポートフォリオ整備、職務経歴書、面接対策
「何を学ぶか」より「何を作ってGitHubに公開するか」を意識することが転職成功の鍵だ。動くものをつくり続けることで、技術的な理解と自信が同時に育つ。

エンジニア転職ポートフォリオ完全ガイド
採用担当が本当に見ているポートフォリオの評価基準。AI系ポートフォリオの作り方にも応用できる